The Future of Software Engineering: How AI Is Reshaping Roles and Skills (2025)
Artificial intelligence is no longer a futuristic concept discussed in conference keynotes; it’s rapidly becoming the default collaborator for software engineers worldwide. Whether you’re bootstrapping a startup’s backend, crafting pixel-perfect frontends, or managing complex legacy systems, understanding how to effectively partner with Large Language Models (LLMs) is shifting from a novelty to a necessity.
Just a year or two ago, many of us viewed tools like GitHub Copilot as autocomplete on steroids – helpful, but supplementary. Fast forward to 2025, and it’s increasingly common to initiate entire projects by brainstorming with models like Claude 3.7 Sonnet or GPT-4o, often receiving functional code scaffolds within minutes. This dramatic acceleration changes the very nature of engineering work. We’re spending less time writing boilerplate loops and more time defining system architecture, validating AI-generated outputs, and making critical product decisions.
But harnessing this speed requires more than just access to an API key. Without structured workflows and a critical mindset, it’s easy to waste hours wrestling with an LLM stuck in a loop of incorrect fixes. This post dives into the practical realities of AI-assisted software engineering based on firsthand experience: the workflows that boost productivity, the pitfalls to avoid, the skills that matter most now, and a glimpse into where this rapid evolution is heading.
The Shift: Why AI Collaboration Matters Now More Than Ever
The transition is palpable. Internal benchmarks and industry studies alike point towards significant productivity gains. GitHub’s research indicated developers using Copilot completed tasks 55% faster. An independent academic replication confirmed this, finding a 55.8% speedup. While these numbers resonate with our own experience, particularly on greenfield projects, the true impact goes beyond mere speed.
AI is forcing a re-evaluation of where engineers deliver the most value. If an AI can generate boilerplate code, unit tests, or even simple UI components reliably, the engineer’s role elevates towards:
- Strategic Definition: Clearly articulating the what and why of a feature or system.
- Architectural Design: Making high-level decisions about structure, dependencies, and scalability.
- Rigorous Validation: Ensuring the AI’s output is not just functional but also correct, secure, efficient, and maintainable.
- Complex Problem Solving: Tackling the non-standard, ambiguous challenges that require human ingenuity and domain expertise.
Mastering this new dynamic requires adapting our workflows.
Evolving Workflows: From Design Docs to Dual-Model Reviews
Integrating AI effectively means rethinking traditional development steps. Here’s how our process has evolved:
| Traditional Step (circa 2023) | AI-Assisted Step (2025) | Rationale |
| Sketch requirements in a doc (often skipped) | Co-author a detailed Design Doc in Markdown with an LLM | Provides clear “contract” for AI, version controllable, aligns team. |
| Hand-code boilerplate/use basic templates | Use LLMs to generate scaffolding, tests, and basic logic | Frees up human engineers for higher-level tasks, faster iteration. |
| Manual code review by peers | Dual-Model AI Review followed by focused human oversight | Catches more issues, reduces bias, speeds up initial review cycles. |
| Team discussion/alignment in Slack/Meetings | Blend human chat with LLM-generated summaries & analysis | Efficiently surfaces key points, tracks decisions, aids asynchronous work. |
Design Docs as AI Contracts
We now mandate a Markdown design document for every project, regardless of size. This document, co-authored with an LLM to ensure clarity and completeness, typically covers:
- Goal: What problem does this solve?
- Interfaces: APIs, CLIs, data formats.
- Tech Stack: Languages, frameworks, key libraries, versions (e.g., Python 3.11, Rust 1.78).
- Dependencies: External services, databases.
- Data Models: Schema definitions.
- User Stories/Acceptance Criteria: How do we know it’s done?
- Milestones: Phased rollout plan.
This doc lives in the project repository. IDE extensions (like Cursor’s or custom setups) can automatically include it in the context for every prompt. This simple step drastically reduces the chances of the LLM “guessing” the wrong framework, inventing file structures, or ignoring project constraints. It acts as a clear contract for the AI collaborator.
The Power of the Dual-Model Review Loop
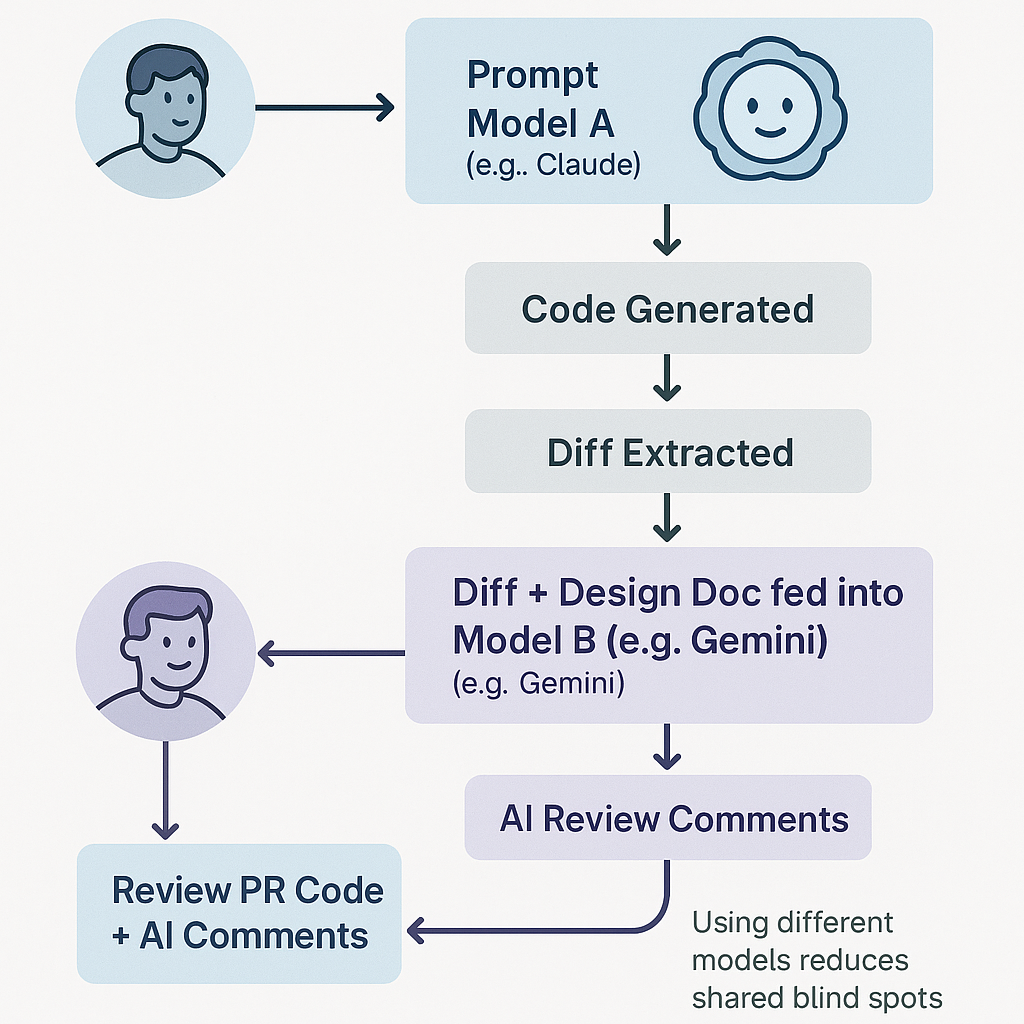
Code review is fundamental to quality. We’ve augmented our human review process with a two-stage AI review, leveraging different models to catch a wider range of issues:
- Generate: Use your primary LLM (e.g., Claude 3.5 Sonnet, often strong for frontend/TypeScript) to generate code based on the design doc and specific prompts.
- Commit & PR: Follow standard Git practices – create a pull request with clean, scoped commits.
- Extract Diff: Copy the changes (git diff main… | pbcopy or similar).
- AI Review 1 (Generator Model): Sometimes, asking the generating model to review its own work can catch basic errors or prompt misunderstandings. “Review this diff for adherence to the design doc and best practices.”
- AI Review 2 (Different Vendor): Paste the diff and key design doc sections into a different model (e.g., Gemini 2.5 Pro if you generated with Claude/GPT). Ask specific questions: “Review this diff for potential security vulnerabilities, missing edge case tests, performance bottlenecks, and consistency with Python 3.11 best practices, considering our design doc [link/paste relevant section].”
- Human Oversight: A human engineer now reviews the PR and the AI review outputs. The focus shifts from spotting typos or basic logic errors (often caught by AI) to verifying architectural soundness, complex logic, and subtle requirement mismatches.
Using models from different vendors (e.g., Anthropic vs. Google vs. OpenAI) is crucial. They have different training data, architectures, and inherent biases. One model’s blind spot is often another’s strength. We’ve seen cases where one model confidently hallucinated a non-existent library function, only for the second model to immediately flag it as incorrect, saving significant debugging time.
Navigating the Pitfalls: Common AI Time Sinks and How to Escape Them
While AI accelerates development, it introduces new ways to lose time if you’re not vigilant. Understanding these common failure modes is key to maintaining productivity:
- API Hallucinations & Version Skew: LLMs trained on older data might confidently use deprecated functions, non-existent API endpoints, or incorrect library versions. Mitigation: Always provide version context (e.g., “using React 18”) and cross-reference generated code with official documentation, especially for newer or rapidly changing libraries. Use tools that feed current docs into the context.
- Superficially Correct Tests: AI can generate tests that pass but don’t actually validate the intended logic or cover meaningful edge cases. Mitigation: Treat AI-generated tests as a starting point. Critically evaluate what they assert. Manually add tests for complex logic, failure conditions, and known edge cases. Demand tests that fail when logic is broken.
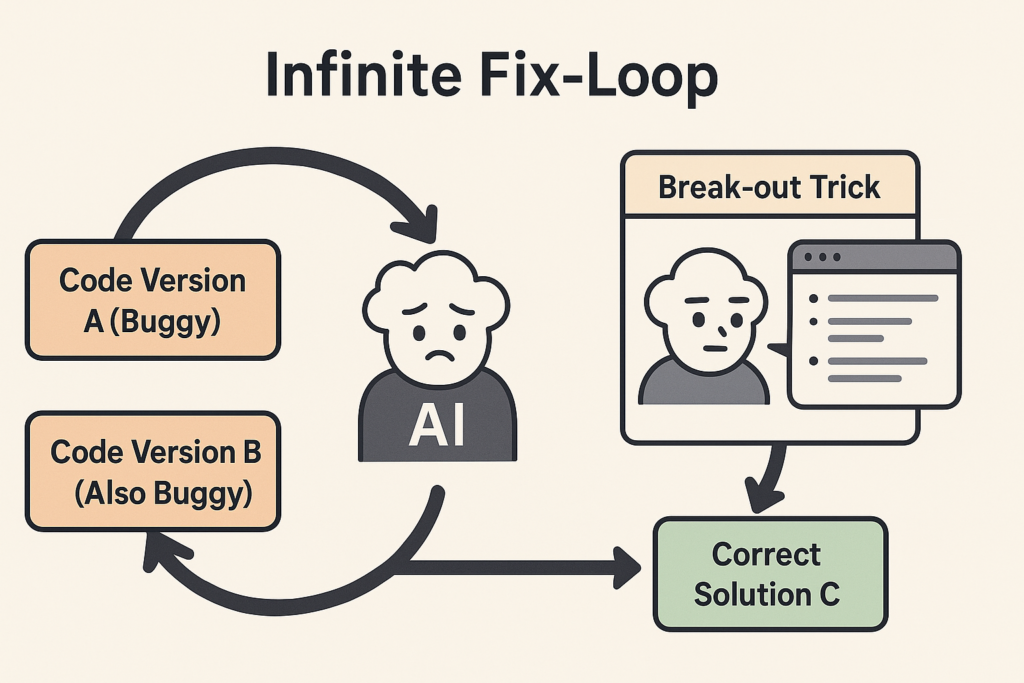
- The Infinite Fix-Loop: The model gets stuck oscillating between two slightly flawed solutions (Variant A -> Variant B -> Variant A…) without converging. This often happens with complex or poorly defined problems. Mitigation: Use the “Summarize for an Expert” trick: Ask the stuck model: “Summarize the core problem we’re trying to solve, the approaches attempted so far, and why they failed. Explain it like you’re briefing a senior human expert.” Then, paste this structured summary into a fresh chat session or a different LLM. This resets the context and often breaks the loop by reframing the problem.
- Over-Reliance & Skill Atrophy: Relying too heavily on AI for fundamental tasks without understanding the underlying principles can hinder learning and problem-solving skills. Mitigation: Consciously interleave AI generation with manual coding. Take time to read and understand AI-generated code. Debug issues manually sometimes to reinforce fundamentals. Treat AI as a powerful pair programmer, not a replacement for thinking.
The Skills That Matter Most in the AI-First Era
The rise of AI isn’t eliminating engineering jobs, but it is reshaping the skills required to excel. Technical proficiency remains crucial, but the emphasis is shifting towards skills that maximize collaboration with AI:
- Precise Asynchronous Communication: The ability to write exceptionally clear prompts, design documents, bug reports, and code reviews is paramount. Your instructions need to be unambiguous for both human colleagues and AI models to act upon the correct intent. This includes iteratively refining prompts to get desired outputs.
- Adaptability and Continuous Learning: The AI landscape and associated tooling are evolving at breakneck speed. Today’s best-in-class model or workflow might be superseded in six months. Engineers need a mindset geared towards quickly learning, evaluating, and integrating new tools and techniques without friction or dogma.
- Critical Thinking & Engineering Rigor: This is perhaps the most important skill. It involves:
- Validation: Not blindly trusting AI output. Questioning assumptions, verifying logic, and testing thoroughly.
- Debugging: Knowing how to diagnose problems, whether they originate in human or AI-generated code. This might involve reading deeper than before – sometimes even looking at lower-level outputs if performance is critical.
- Systemic Understanding: Seeing the bigger picture beyond the generated function – how does this piece fit into the larger architecture? What are the security, scalability, and maintainability implications?
- Knowing When Not to Use AI: Recognizing tasks where human intuition, creativity, or deep domain knowledge are currently irreplaceable.
We’ve adjusted our hiring process accordingly. We don’t use “prompt-engineering” trivia. Instead, during live coding sessions, candidates can choose their preferred tools, including LLMs. The valuable signal isn’t whether they can get the AI to write code, but how they interact with it. Do they critically evaluate suggestions? Can they explain why an AI suggestion is wrong? Do they refine their prompts thoughtfully? This conversational approach reveals far more about their AI fluency and engineering rigor than any canned test.

Our Current AI-Assisted Toolchain (Snapshot: Q2 2025)
The effectiveness of AI-assisted development hinges on the entire toolchain. Here’s a snapshot of what our team finds effective currently. Note: This stack evolves rapidly; experimentation is key.
| Layer | Tool(s) Chosen | Key Reason |
| IDE | VS Code + Copilot / Cursor | VS Code offers robust core features & Copilot integration. Cursor excels at multi-file context awareness & inline chat/editing. We use both. |
| Generators | Claude 3.5 Sonnet (Frontend/TS) <br> GPT-4o / GPT-4o-mini (Python/Rust) | Models selected based on internal benchmarks for specific language/task performance and pass rates. Sonnet often yields better structured UI code; GPT variants strong on backend logic. |
| Reviewer | Gemini 2.5 Pro | Acts as a crucial “second opinion” due to different training data, helping catch biases or errors missed by the primary generator model. |
| Context Injection | .cursor-rules, github/llm-rules.md, Custom Scripts | Automatically inject project-specific context (language versions, style guides, design doc snippets) into prompts, reducing repetitive setup. |
| Doc Search | IDE Plugins (e.g., Copilot Chat Web Search), Phind, Perplexity | Provide models with access to up-to-date documentation for rapidly evolving frameworks (e.g., latest React, Rust nightly features). |
Beyond Anecdotes: Evidence of AI’s Impact
While personal experiences are illustrative, broader data confirms the trend. Beyond the GitHub Copilot studies, other research highlights the nuances:
- Stack Overflow’s 2023 Developer Survey: Showed rapid adoption, with 44% of developers using AI tools in their workflow and another 26% planning to. This indicates a massive shift in under a year.
- Code Quality Concerns: An early 2024 white paper cautioned that while AI speeds up development, relying solely on AI without rigorous review can lead to code with subtle bugs, security flaws, or maintainability issues. This reinforces the need for strong validation processes like the dual-model review.
- Task Variability: Productivity gains aren’t uniform. Studies suggest AI provides the biggest boost for repetitive tasks, boilerplate generation, and unfamiliar domains, while complex debugging or novel algorithm design still heavily relies on human expertise.
The data paints a clear picture: AI significantly enhances productivity, but quality control and strategic application remain critical human responsibilities.
Peering Towards 2030: What AI Will Own (and What Remains Human)
Predicting the future is fraught, but current trajectories suggest a likely division of labor:
- Likely AI Domain by 2030:
- Boilerplate & Scaffolding: Generating standard code structures, setup scripts, basic CRUD operations.
- Exhaustive Unit & Integration Testing: Writing comprehensive tests based on schemas and specifications.
- Code Translation & Refactoring: Migrating codebases between languages or frameworks based on defined rules.
- Simple UI Component Generation: Creating standard UI elements based on design systems.
- Documentation Generation: Drafting initial documentation from code and specifications.
- Likely Human Domain by 2030:
- Problem Framing & Strategic Alignment: Defining why a piece of software should exist, who it serves, and how it fits into the larger business or product strategy.
- Complex System Architecture & Design: Making high-level decisions about interactions, trade-offs, and long-term maintainability for novel or intricate systems.
- Novel Algorithm Development: Creating fundamentally new approaches to solve problems.
- Ethical Considerations & User Trust: Ensuring software is fair, unbiased, secure, and respects user privacy.
- Ambiguous Problem Solving: Navigating requirements that are unclear, conflicting, or require deep domain expertise and creative thinking.
- Mentorship & Team Leadership: Guiding and developing other engineers, fostering collaboration, and setting technical vision.
The engineer’s role becomes less about typing code and more about orchestrating AI agents, defining problems, validating solutions, and making strategic decisions.
Hiring in the AI Era: Seeking Fluency, Not Just Prompters
Job titles likely won’t change drastically overnight – we’ll still hire “Software Engineers.” However, the expectations within that role are evolving. Our hiring process now emphasizes:
- Live AI Collaboration: Allowing candidates to use LLMs during coding interviews.
- Probing for Reflection: Asking questions like, “The AI suggested X, why did you choose to implement Y instead?” or “Walk me through how you validated that AI-generated test.”
- Rewarding Curiosity & Adaptability: Valuing candidates who experiment with prompts, check alternative models, or question AI suggestions over those who rely purely on recall or blindly accept the first output.
We don’t anticipate a widespread, distinct role of “Prompt Engineer” within software teams. Instead, we expect a higher demand for “AI-Fluent” Software Engineers – those who seamlessly integrate AI tools into their workflow, understand their capabilities and limitations, and maintain strong core engineering principles.
Open Challenges and the Road Ahead
Despite the rapid progress, significant challenges remain:
- Knowledge Cutoff & Real-time Information: Models are often trained on data that’s months old. New library releases, framework updates, or security vulnerabilities emerge faster than models are retrained. Workaround: Develop robust context injection pipelines (feeding current docs, using web search plugins) and maintain vigilance.
- Vendor Lock-in & Tooling Fragmentation: Specific IDEs or tools might be tightly coupled to certain models, making it hard to switch. Proprietary prompt extensions can reduce portability. Workaround: Keep core prompts relatively generic and portable; prefer open standards where possible.
- Governance, Security & Licensing: AI can inadvertently introduce code with problematic licenses, leak secrets if trained on sensitive data, or introduce subtle security flaws. Workaround: Human oversight remains critical. Implement automated code scanning tools (SAST, DAST, license checkers) but don’t rely on them exclusively. Clear data governance policies for using internal code with external models are essential.
- Cost Management: Frequent calls to powerful AI models can become expensive, especially for large teams or extensive automated workflows. Workaround: Monitor API usage, use smaller/cheaper models for simpler tasks, implement caching strategies, and optimize prompting.
- Evaluation & Benchmarking: Objectively measuring the quality of AI-generated code and the effectiveness of different models/prompts remains challenging. Workaround: Develop internal benchmarks relevant to your specific domain and tech stack; combine quantitative metrics with qualitative human review.
Practical Tips You Can Implement Tomorrow
Ready to improve your AI-assisted workflow? Try these actionable tips:
- Keep Design Docs Concise: Aim for key details to fit within the model’s context window (often ~10k-100k+ tokens, check your model’s limits). Use summaries for very large docs.
- Use Folder-Specific Rules: Configure your tools (like .cursor-rules or similar) to provide different context based on the directory (e.g., frontend/ gets React context, backend/ gets Rust/Python context).
- Alias Common Commands: Create shell aliases for frequent tasks, like alias gdiff=’git diff main… | pbcopy’ to quickly copy diffs for review prompts.
- Leverage the “Summarize for Expert” Trick: When stuck in a loop, ask the model to summarize the problem and failed attempts. Paste this into a fresh chat or different model.
- Prefer Small, Focused PRs: AI agents (and human reviewers) handle smaller, well-defined changes much more effectively than large, monolithic ones. Break down tasks accordingly.
- Version Your Prompts: Store effective prompts in a shared team resource or version control; treat them like code.
- Share Learnings: Encourage team members to share successful prompting techniques, tool discoveries, and common pitfalls.
Where to Explore Next
This field is moving incredibly fast. Staying curious and experimenting is key.