
Humans Powering the Machines
There is a hype around AI built on top of recent success with deep learning. But there is one unsolved piece in the equation. AI needs to learn from humans.

(Matan Segev, pexels.com)
When I heard about machine learning for the first time, I thought it would just simply work like this. Let’s say I want to classify pictures of dogs or cats. I would show the model a picture of a dog and a picture of a cat and it would learn to separate the two classes. Unfortunately, that’s not the case. To get high accuracy with deep learning models trained from scratch we need thousands of images for each class.
For some, this might not sound like a big deal. But if you assume it takes you 5 seconds per image to determine its a dog or cat and add it to a dataset, you can label 30 images per minute. Or 1,800 images per hour. For a dataset consisting of 10,000 images (5,000 per class), we end up spending around 5h30min. We could outsource this task to an annotation company. They would annotate each image multiple times by multiple annotators and have an additional quality control person looking over it. So 5h turn into 20h. With a cost of 1$/h, this is still moderate. But how about labeling 1 Million images? And what about image segmentation, where you can spend up to 1h per image?
And then came Transfer Learning
Probably the solution with the widest adoption to solve this absurd problem is called transfer learning. The idea is, instead of training a deep neural network from scratch we use a pre-trained model from another dataset. The low-level features from the pre-trained model generalize very well so only have to fine-tune the last layer. We essentially use a deep learning model as a feature extractor. The classifier on top can be anything ranging from an SVM to a linear layer.
The beauty of this approach is, that the number of samples needed to train a model drops significantly. In case you didn’t know, in object detection or segmentation we already use transfer learning. All those models from Deeplab, Mask-RCNN to the latest ones from the research are typically built on a backbone model pre-trained on a dataset like ImageNet. That’s why object detection works with just a few thousand samples.
Our human annotators now have to annotate less. But a lot of their work is still inefficient. Are all samples equally important? Can we automate human annotation? Can machines annotate data for other machines?
Active Learning
One of the questions I often get asked is whether we can teach machines to annotate data for other machines. The answer is no. Data annotation is all about providing ground-truth data for the machine learning model. The goal is to provide as accurate data as possible. If we allow one machine to annotate for another machine the latter one’s accuracy kind of bounded by the first one. Flaws learned from the first model would propagate or become worse.
So we can’t use machines to do the annotation but can they help humans to speed up the task? Yes, indeed they can. Nowadays under the umbrella of active learning, we understand a model that predicts newly unseen samples and gives confidence. Is the confidence low we assume the sample is hard and the human should annotate it.
Additionally, the prediction from the model can be used as an initial guess for the human annotator. This process is now used by almost every company working with large datasets and requiring data annotation. But also this method has its drawbacks. When I exchange with ML engineers they often complain that they used active learning from the beginning and after a while figured out it didn’t bring any value compared to randomly selected samples.
I think it’s really important to try out and properly verify the various methods available before investing heavily in the pipeline. Furthermore, just because a method works on one academic dataset it doesn’t mean it works on yours.
What’s next? Semi-Supervised Learning
Last year, I spent a lot of time reading up with the latest research on semi-supervised and self-supervised learning. Recent advancements in the field make them the most promising approach. The idea is that we train a model on the raw data using contrastive losses. For example, we take an image, perform various image augmentations such as random crop, color changes and then train a model to embed augmentations from the same image close to each other whereas different images are far apart. I highly recommend having a look at recent publications such as Contrastive Multiview Coding, Contrastive Predictive Coding or SimCLR.
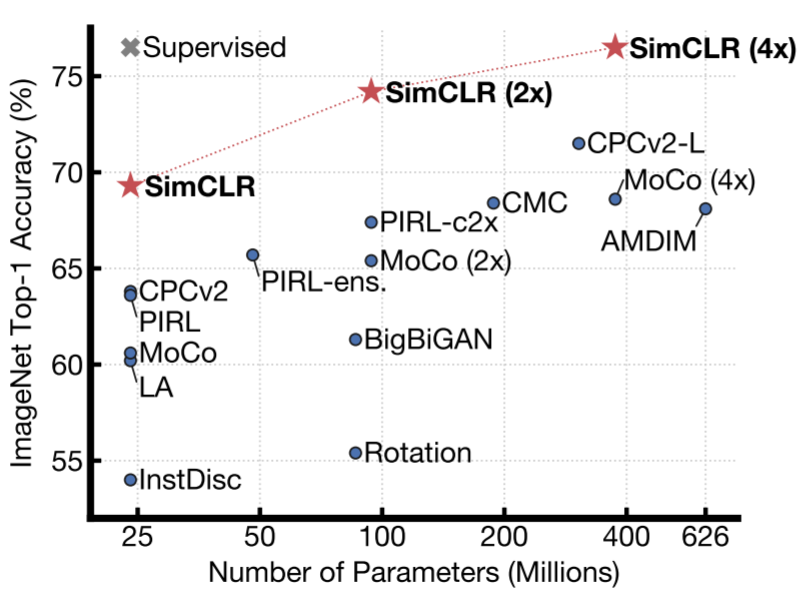
(From SimCLR paper, 2020)
I imagine in the future we can build a model that learns from the just collected and raw dataset using self-supervision. A few samples get selected which will be sent for annotation. The model gets fine-tuned using the annotations for a specific task. However, there will always be one step where a human needs to annotate a sample even if it might only be a fraction of the work we have today.